Memcached高可用
Memcached高可用
Memcached 高可用所使用的解决方法就是 Consistent Hashing。在该算法的帮助下,Memcached 实例数量的变化将只可能导致其中的一小部分键的哈希值发生改变。
Memcached高可用详解
在企业级应用中,我们常常强调一个系统需要拥有高可用性和高可靠性。而对于一个组成而言,其需要能够稳定地运行,并在出现异常的时候尽量使得异常的影响限制在某个特定的范围内,而不会导致整个系统不能正常工作。而且在出现异常之后,该组成需要能较为容易地恢复到正常的工作状态。
那么 Memcached 需要什么样的高可用性呢?在讲解这个问题之前,我们先来看看在一个大型服务中 Memcached 所组成的服务端缓存是什么样的:
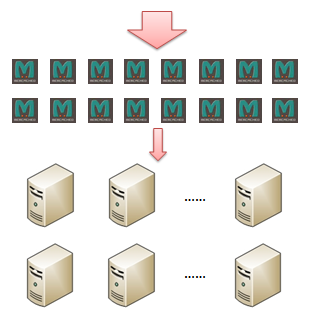
从上图中可以看到,在一个大型服务中,由 Memcached 所组成的服务端缓存实际上是由非常多的 Memcached 实例组成的。在前面我们已经介绍过,Memcached 实例实际上是完全独立的,不存在 Memcached 实例之间的相互交互。因此在其中一个发生了故障的时候,其它的各个 Memcached 服务实例并不会受到影响。如果一个拥有了 16 个 Memcached 实例的服务端缓存系统中的一个 Memcached 实例发生了故障,那么整个系统将还有 93.75% 的缓存容量可以继续工作。虽然缓存容量的减少会略微增加其后的各个服务实例的压力,但是一个应用所经历的负载波动常常比这个大得多,因此该服务应该还是能够正常工作的。
而这也恰恰表明了 Memcached 所具有的独立性的正确性。由于 Memcached 本身致力于创建一个高效而且简单,却具有较强扩展性的缓存组件,因此其并没有强调数据的安全性。一旦其中的一个 Memcached 实例发生了故障,那么我们还可以从数据库及服务端再次计算得到该数据,并将其记录在其它可用的 Memcached 实例上。
我想您读到这里一定会想:“不,还有一个问题,那就是由于 Memcached 实例的个数变化会导致哈希计算的结果发生变化,从而导致所有对数据的请求会导向到不正确的 Memcached 实例,使得由 Memcached 实例集群所提供的缓存服务全部失效,从而导致数据库的压力骤增。”
是的,这也是我曾经有所顾虑的地方。而且这不仅仅在服务端缓存失效的时候存在。只要服务端缓存中Memcached 实例的数量发生了变化,那么该问题就会发生。
Memcached 所使用的解决方法就是 Consistent Hashing。在该算法的帮助下,Memcached 实例数量的变化将只可能导致其中的一小部分键的哈希值发生改变。那该算法到底是怎么运行的呢?
首先请考虑一个圆,在该圆上分布了多个点,以表示整数 0 到 1023。这些整数平均分布在整个圆上:
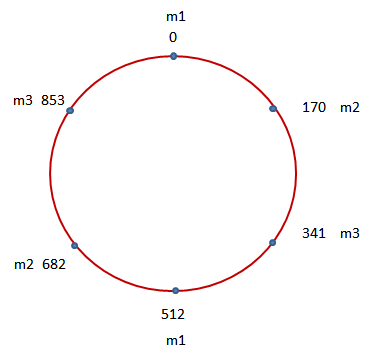
而在上图中,我们则突出地显示了 6 个蓝点。这六个蓝点基本上将该圆进行了六等分。而它们所对应的就是在当前 Memcached 缓存系统中所包含的三个 Memcached 实例 m1,m2 以及 m3。好,接下来我们则对当前需要存储的数据执行哈希计算,并找到该哈希结果 900 在该圆上所对应的点:
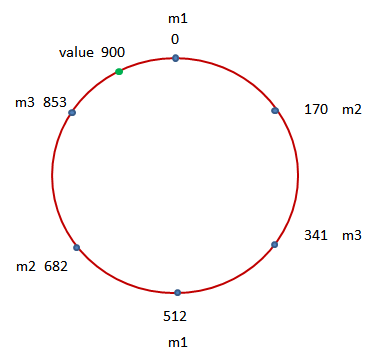
可以看到,该点在顺时针距离上离表示 0 的那个蓝点最近,因此这个具有哈希值 900 的数据将记录在 Memcached 实例 m1 中。
如果其中的一个 Memcached 实例失效了,那么需要由该实例所记录的数据将暂时失效,而其它实例所记录的数据仍然还在:
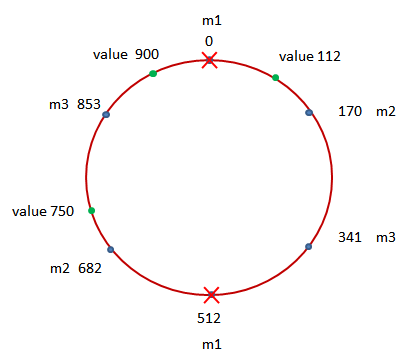
从上图中可以看到,在 Memcached 实例 m1 失效的情况下,值为 900 的数据将失效,而其它的值为 112 和 750 的数据将仍然记录在 Memcached 实例 m2 及 m3 上。也就是说,一个节点的失效现在将只会导致一部分数据不再在缓存系统中存在,而并没有导致其它实例上所记录的数据的目标实例发生变化。
但是我们还不得不考虑另一个问题,那就是在一个服务的服务端缓存仅仅由一个或几个 Memcached 实例组成的情况。在这种情况下,其中一个 Memcached 实例失效是较为致命的,因为数据库以及服务器实例将接收到大量的需要进行复杂计算的请求,并将最终导致服务器实例和数据库过载。因此在设计服务端缓存时,我们常常采取超出需求容量的方法来定义这些缓存。例如在服务实际需要 5 个 Memcached 结点时我们设计一个包含 6 个节点的服务端缓存系统,以增加整个系统的容错能力。





