Memcached内存管理
Memcached内存管理
Memcached 使用了一种叫 Slab 的结构来进行内存管理。在该分配算法中,内存将按照 1MB 的大小划分为页,而该页内存则会继续被分割为一系列具有相同大小的内存块。
Memcached内存管理详解
在使用缓存时,我们不得不考虑的一个问题就是如何对这些缓存数据的生存期进行管理。这其中包括如何使一个记录在缓存中的数据过期,如何在缓存空间不够时执行数据的替换等。因此在本节中,我们将对 Memcached 的内存管理机制进行介绍。
首先我们来看一看 Memcached 的内存管理模型。通常情况下,一个内存管理算法所最需要考虑的问题就是内存的碎片化(Fragmentation):在长时间地分配及回收之后,被系统所使用的内存将趋向于散落在不连续的空间中。这使得系统很难找到连续内存空间,一方面增大了内存分配失败的概率,另一方面也使得内存分配工作变得更为复杂,降低了运行效率。
为了解决这个问题,Memcached 使用了一种叫 Slab 的结构。在该分配算法中,内存将按照 1MB 的大小划分为页,而该页内存则会继续被分割为一系列具有相同大小的内存块:
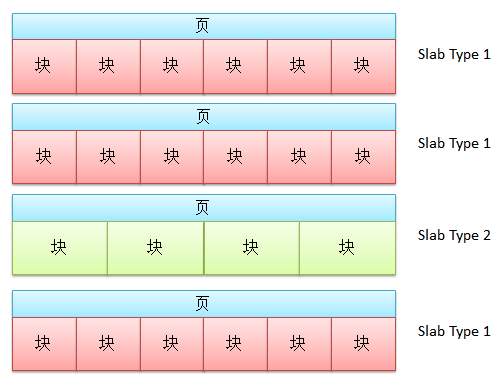
因此 Memcached 并不是直接根据需要记录的数据的大小来直接分配相应大小的内存。在一条新的记录到来时,Memcached 会首先检查该记录的大小,并根据记录的大小选择记录所需要存储到的 Slab 类型。接下来,Memcached 就会检查其内部所包含的该类型 Slab。如果这些 Slab 中有空余的块,那么 Memcached 就会使用该块记录该条信息。如果已经没有 Slab 拥有空闲的具有合适大小的块,那么 Memcached 就会创建一个新的页,并将该页按照目标 Slab 的类型进行划分。
一个需要考虑的特殊情况就是对记录的更新。在对一个记录进行更新的时候,记录的大小可能会发生变化。在这种情况下,其所对应的 Slab 类型也可能会发生变化。因此在更新时,记录在内存中的位置可能会发生变化。只不过从用户的角度来说,这并不可见。
Memcached 使用这种方式来分配内存的好处则在于,其可以降低由于记录的多次读写而导致的碎片化。反过来,由于 Memcached 是根据记录的大小选择需要插入到的块类型,因此为每个记录所分配的块的大小常常大于该记录所实际需要的内存大小,进而造成了内存的浪费。当然,您可以通过 Memcached 的配置文件来指定各个块的大小,从而尽可能地减少内存的浪费。
但是需要注意的是,由于默认情况下 Memcached 中每页的大小为 1MB,因此其单个块最大为 1MB。除此之外,Memcached 还限制每个数据所对应的键的长度不能超过 250 个字节。
一般来说,Slab 中各个块的大小以及块大小的递增倍数可能会对记录所载位置的选择及内存利用率有很大的影响。例如在当前的实现下,各个 Slab 中块的大小默认情况下是按照 1.25 倍的方式来递增的。也就是说,在一个 Memcached 实例中,某种类型 Slab 所提供的块的大小是 80K,而提供稍大一点空间的 Slab 类型所提供的块的大小就将是 100K。如果现在我们需要插入一条 81K 的记录,那么 Memcached 就会选择具有 100K 块大小的 Slab,并尝试找到一个具有空闲块的 Slab 以存入该记录。
同时您也需要注意到,我们使用的是 100K 块大小的 Slab 来记录具有 81K 大小的数据,因此记录该数据所导致的内存浪费是 19K,即 19% 的浪费。而在需要存储的各条记录的大小平均分布的情况下,这种内存浪费的幅度也在 9% 左右。该幅度实际上取决于我们刚刚提到的各个 Slab 中块大小的递增倍数。在 Memcached 的初始实现中,各个 Slab 块的递增倍数在默认情况下是 2,而不是现在的 1.25,从而导致了平均25%左右的内存浪费。而在今后的各个版本中,该递增倍数可能还会发生变化,以优化 Memcached 的实际性能。
如果您一旦知道了您所需要缓存的数据的特征,如通常情况下数据的大小以及各个数据的差异幅度,那么您就可以根据这些数据的特征来设置上面所提到的各个参数。如果数据在通常情况下都比较小,那么我们就需要将最小块的大小调整得小一些。如果数据的大小变动不是很大,那么我们可以将块大小的递增倍数设置得小一些,从而使得各个块的大小尽量地贴近需要存储的数据,以提高内存的利用率。
还有一个值得注意的事情就是,由于 Memcached 在计算到底哪个服务实例记录了具有特定键的数据时并不会考虑用来组成缓存系统中各个服务器的差异性。如果每个服务器上只安装了一个 Memcached 实例,那么各个 Memcached 实例所拥有的可用内存将存在着数倍的差异。但是由于各个实例被选中的概率基本相同,因此具有较大内存的 Memcached 实例将无法被充分利用。我们可以通过在具有较大内存的服务器上部署多个 Memcached 实例来解决这个问题:
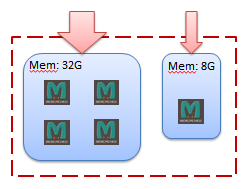
例如上图所展示的缓存系统是由两个服务器组成。这两个服务器中的内存大小并不相同。第一个服务器的内存大小为 32G,而第二个服务器的内存大小仅仅有 8G。为了能够充分利用这两个服务器的内存,我们在具有 32G 内存的服务器上部署了 4 个 Memcached 实例,而在只有 8G 内存的服务器上部署了 1 个 Memcached 实例。在这种情况下,32G 内存服务器上的 4 个 Memcached 实例将总共得到 4 倍于 8G 服务器所得到的负载,从而充分地利用了 32G 内存服务器上的内存。
当然,由于缓存系统拥有有限的资源,因此其会在某一时刻被服务所产生的数据填满。如果此时缓存系统再次接收到一个缓存数据的请求,那么它就会根据 LRU(Least recently used)算法以及数据的过期时间来决定需要从缓存系统中移除的数据。而 Memcached 所使用的过期算法比较特殊,又被称为延迟过期(Lazy expiration):当用户从 Memcached 实例中读取数据的时候,其将首先通过配置中所设置的过期时间来决定该数据是否过期。如果是,那么在下一次写入数据却没有足够空间的时候,Memcached 会选择该过期数据所在的内存块作为新数据的目标地址。如果在写入时没有相应的记录被标记为过期,那么 LRU 算法才被执行,从而找到最久没有被使用的需要被替换的数据。
这里的 LRU 是在 Slab 范围内的,而不是全局的。假设 Memcached 缓存系统中的最常用的数据都存储在 100K 的块中,而该系统中还存在着另外一种类型的 Slab,其块大小是 300K,但是存在于其中的数据并不常用。当需要插入一条 99K 的数据而 Memcached 已经没有足够的内存再次分配一个 Slab 实例的时候,其并不会释放具有 300K 块大小的 Slab,而是在 100K 块大小的各个 Slab 中找到需要释放的块,并将新数据添加到该块中。





