Redis线程模型
Redis事件
不是讲线程模型吗?和事件有什么关系?实际上 Redis 是一个事件驱动程序,大白话理解一下:就是通过事件的方式来运行 Redis 的。比如客户端向服务端发起一个 get 请求,在做好了建连、发送请求、响应请求、关闭连接等准备操作后,就触发了一个事件。所以在了解线程模型之前,先来看看事件。
Redis 的事件分为两种,分别是文件事件和时间事件两种。
文件事件
文件事件是 socket 的一个抽象,客户端发送请求到服务端,会先建立连接,然后通过连接发送命令请求,其中每个连接就是一个 socket。对于一个 Redis 服务端,在同一时刻会有很多 socket 连接,每一个 socket 都可以理解成一个文件事件。
每产生一个文件事件后,就将其交给文件事件处理器去处理,文件事件处理器是由 I/O 多路复用处理器、文件事件分发器、事件处理器几部分组成。服务端在接收到请求后,是怎么工作的呢?
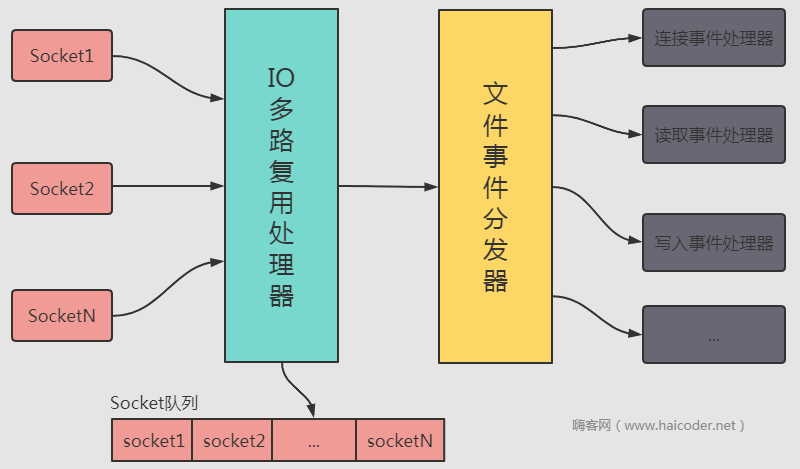
从上图可以看出,当客户端发送请求到服务端后;
- 首先服务端通过 I/O 多路复用处理器接收文件事件(即一个一个的 socket),并将接收到的文件事件插入到事件队列中。
- 接收文件事件分发器将接收到的时间按照事件类型分发给不同的事件处理器去执行;比如客户端发送了一个 get 请求,文件事件处理器就会将该请求发送给读取事件处理器去执行。
- 相应的事件处理器接收到请求后,就去执行相应的操作,然后将相应的结果返回。
- 当一个事件处理完毕并返回相应的结果后,文件事件分发器继续处理事件队列中的下一个请求,重复上述的动作,直到没有文件事件可以被处理。这个流程其实有点像生产者消费者的样子。
I/O 对路复用处理器在 Redis 中用很多种实现,比如 epool、select、evport、kquene 等等,Redis 服务端在运行的时候会根据预先设定的 include 宏定义来选择效率最高的模型去处理网络事件。
以上基本上就是 Redis 的线程工作模型,不过还差一点就是文章开头讲到的另外一种事件类型,时间事件。
时间事件
时间事件,顾名思义就是和时间相关的一些事件操作。举个例子,在 Redis 中最不陌生的应该就是各种定时处理器,每隔一段时间就出发一个操作。具体的应用如 RDB 和 AOF 文件定时做持久化操作;如果集群是主从架构的,定时将主库上的数据同步给从库,定期发送心跳信息给集群内各个节点,检查节点是否还在正常提供服务;定期检查库里面设置了过期时间的 key 并将已过期的 key 从内存中提出等等一些实际应用。
时间事件是怎么实现的?
Redis 将所有时间事件通过链表串联起来,每个结点代表一个时间事件,每个结点上存储着当前时间下一次要发生的时间点;每隔一段时间,该链表就会被遍历一次,发现那个时间事件该执行就去执行对应的事件,然后更新其下一次应该执行的时间点。
文件事件和时间事件是怎么配合工作的?
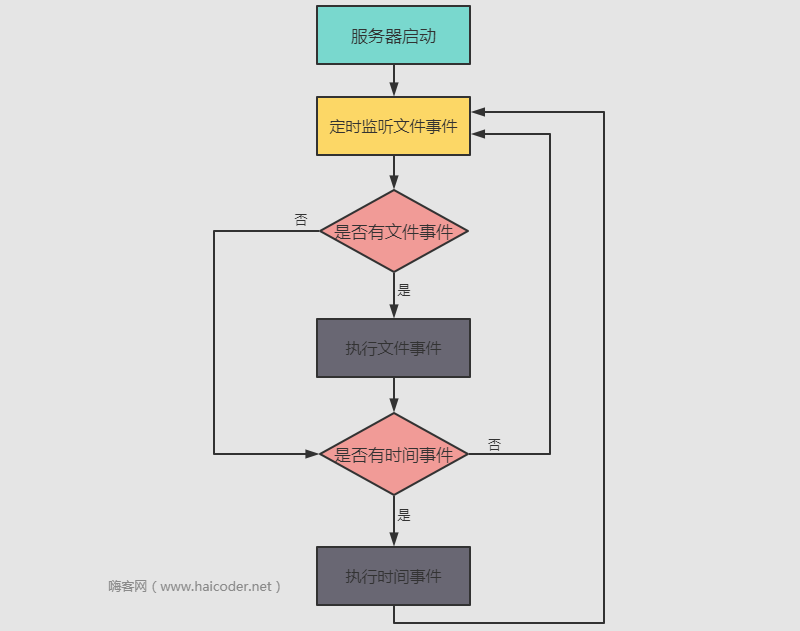
如上图,文件事件和时间事件配合工作流程图。
- 服务器启动后,开始监听文件事件,如果在一段时间内有监听到文件事件,则会执行文件事件,执行完文件事件后,开始遍历时间事件,这里需要注意的是,如果文件事件执行时间过长,不会让其一直执行,而是暂停,等待下一个周期在继续执行。
- 文件事件执行完,开始遍历执行时间事件,遇到需要执行的时间事件,比如定时持久化 RDB 和 AOF 等比较耗时的操作时,会 Fork 出一个子线程去执行,而不会夯住当前线程。
- 依次循环上述流程,就完成了文件事件和时间事件的配合工作的流程了。
Redis6.0为什么要引入多线程
相信很多朋友已经知道了,2020 年 Redis 官方在 5 月份发布多了多线程版本,不过默认是不开启的,可通过 conf 配置开启。从目前 Redis 在实际生产环境中的使用情况看,其每秒钟支持的吞吐量已经非常高了。Redis 发展到目前,其主要的性能瓶颈主要在网络 I/O 和内存两个方面。
- 内存容量问题:如果采用集群部署的方式,可以通过部署多个端口,使得总容量得到提升,在一定程度上可以解决内存的问题。
- 网络 I/O 问题:在实际生产环境中,Redis 在执行命令时计算基于内存是可以在很快时间内完成的,但是数据传输过程中需要经过网络 I/O 操作,这一步才是真正耗时所在。所以 Redis 在 6.0 版本引入了所谓的多线程,其主要是在做网络 I/O 操作的时候采用了多线程的方式加快 I/O 操作,而命令的执行还是采用单线程进行工作的。





