LengthFieldBasedFrameDecoder
LengthFieldBasedFrameDecoder通用编解码教程
前面我们已经了解到了定长解码器,行解码器和分割符解码器,其实在大多数的协议中在协议头中会携带长度属性,用于标识消息体或者整包消息的长度。由于基于长度解码需求的通用性,为了降低用户的协议开发难度,Netty 就提供了 LengthFieldBasedFrameDecoder。自动屏蔽了 TCP 底层的拆包和粘包问题,只需要传入正确的参数,即可轻松解决 “读半包” 问题。
LengthFieldBasedFrameDecoder用法
基于长度拆包
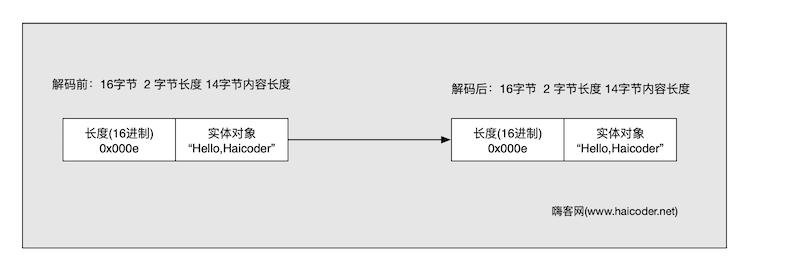
上面这个数据包协议是比较常见的,它有两个区域,前面的 0x000e 是 16 进制的数据,十进制表示 14。它明示了数据内容的长度是 14。我们可以数一下,后面的实体对象里面的数据的长度正好是 14。
LengthFieldBasedFrameDecoder 可以使用下面的构造方法来实现该协议,对应构造函数如下:
/**
* maxFrameLength:表示的是包的最大长度,超出包的最大长度 netty 将会做一些特殊处理
*lengthFieldOffset:长度域的偏移量
*lengthFieldLength:长度域长度
*/
public LengthFieldBasedFrameDecoder(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength);
我们具体实现:
new LengthFieldBasedFrameDecoder(Integer.MAX,0,2);
这边表示长度域的长度为 2,偏移量为 0。报文最大长度为 Integer 的最大值。
基于长度的截断拆包
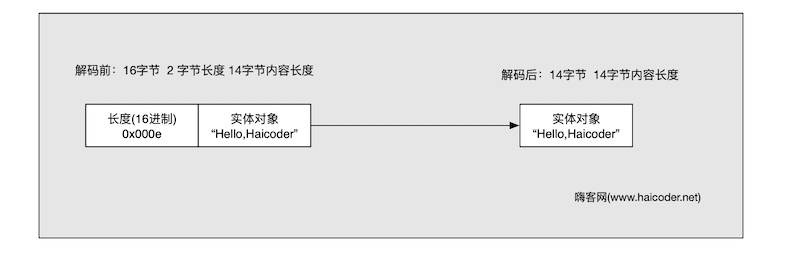
解码前,一共是 16 字节,它有 2 个字节表示长度,14 字节表示内容,在解码后,就只剩 14 字节长度的内容了。它对应的构造函数如下:
/**
* @param maxFrameLength:表示的是包的最大长度,超出包的最大长度 netty 将会做一些特殊处理
* @param lengthFieldOffset:长度字段的偏移量
* @param lengthFieldLength:长度字段的长度
* @param lengthAdjustment:要添加到长度字段值的补偿值,如果是负数,表示启始位置往前挪几字节。如果是正数,就往后挪。
* @param initialBytesToStrip:表示获取完一个完整的数据包之后,忽略对应的 initialBytesToStrip 字节的数据
*
*/
public LengthFieldBasedFrameDecoder(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip)
我们具体实现:
new LengthFieldBasedFrameDecoder(Integer.MAX, 0, 2, 0, 2);
我们将最后一个参数是对应的 initialBytesToStrip 变量, 设置为 2。所以会忽略前面的 2 字节,就将表示长度的数据给丢弃,应用解码器就会是不带长度域的数据包了。
基于偏移长度的拆包
因为协议的种类很多,并不是所有的协议都会将长度属性放在消息的开始地方,当标识消息长度的属性位于消息头的中间或者尾部的时候,我们需要使用 lengthFieldOffset 属性来表示。
对应的构造函数如下
/**
* maxFrameLength:表示的是包的最大长度,超出包的最大长度 netty 将会做一些特殊处理
*lengthFieldOffset:长度域的偏移量
*lengthFieldLength:长度域长度
*/
public LengthFieldBasedFrameDecoder(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength);
我们具体实现如下:
new LengthFieldBasedFrameDecoder(Integer.MAX, 4,2);
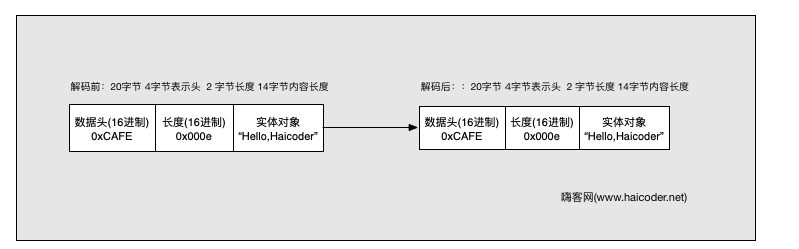
因为 lengthFieldOffset 设置的为 4,所以它会跳过前 4 字节,之后才会计算长度域。它的执行结果如下:
基于可调整长度的拆包
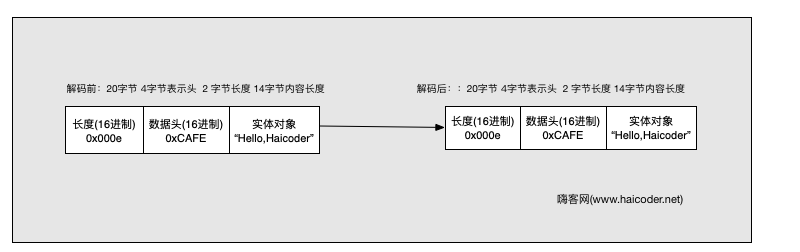
在有的协议中,协议的长度信息放在消息开始的地方,后面不是接报文信息,而是接收的消息头信息,再后面接收消息报文信息。它对应的协议如下:
我们可以使用如下构造函数:
/**
* @param maxFrameLength:表示的是包的最大长度,超出包的最大长度 netty 将会做一些特殊处理
* @param lengthFieldOffset:长度字段的偏移量
* @param lengthFieldLength:长度字段的长度
* @param lengthAdjustment:要添加到长度字段值的补偿值,如果是负数,表示启始位置往前挪几字节。如果是正数,就往后挪。
* @param initialBytesToStrip:表示获取完一个完整的数据包之后,忽略对应的 initialBytesToStrip 字节的数据
*
*/
public LengthFieldBasedFrameDecoder(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip)
具体实现
new LengthFieldBasedFrameDecoder(Integer.MAX, 0, 2, 4, 0);
在上面的包解析图中我们可以看到,该报文的长度为 20 字节。长度域前面没有偏移数据,所以我们将 lengthFieldOffset 设置为 0。而长度本身就占 2 字节,所以 lengthFieldLength 设置为 2。lengthAdjustment 对应的长度补偿机制,我们这边设置为 4 ,表示 4 字节长度是头信息。4 字节后面的数据就是我们需要的内容信息了。
基于偏移可调整长度的截断拆包
在一些协议里面,会包含两个 header,它的报文结构如下:
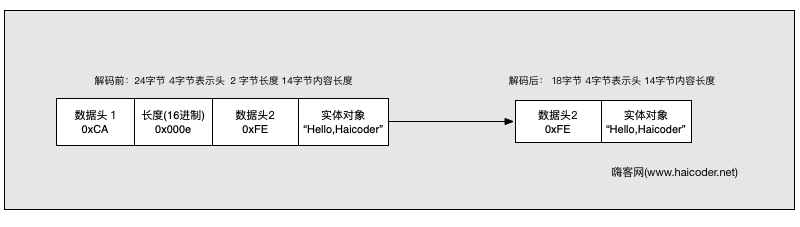
我们可以使用构造函数
/**
* @param maxFrameLength:表示的是包的最大长度,超出包的最大长度 netty 将会做一些特殊处理
* @param lengthFieldOffset:长度字段的偏移量
* @param lengthFieldLength:长度字段的长度
* @param lengthAdjustment:要添加到长度字段值的补偿值,如果是负数,表示启始位置往前挪几字节。如果是正数,就往后挪。
* @param initialBytesToStrip:表示获取完一个完整的数据包之后,忽略对应的 initialBytesToStrip 字节的数据
*
*/
public LengthFieldBasedFrameDecoder(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip)
具体实现
new LengthFieldBasedFrameDecoder(Integer.MAX, 4, 2, 4, 6);
因为 数据头 1 的长度是 4 字节,表示数据报文长度的是 2 字节,所以我们设置 lengthFieldOffset 为 4,lengthFieldLength 为 2。lengthAdjustment 设置为 4 表示报文忽略前面 4 字节,表头数据 2 。initialBytesToStrip 设置为 6 表示丢弃数据头 1 和表示长度的长度为。
基于偏移可调整变异长度的截断拆包
前面所有的长度域表示的是数据内容的长度,如果数据里面长度域表示数据包整体的长度,这个时候该是什么样的情况呢?
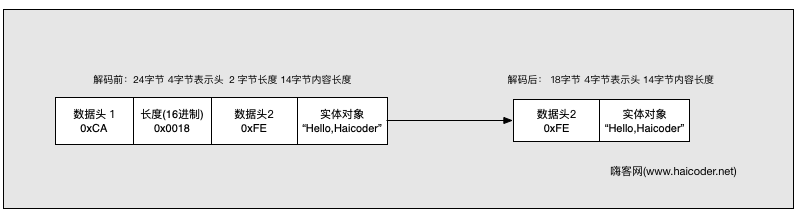
我们可以使用构造函数:
/**
* @param maxFrameLength:表示的是包的最大长度,超出包的最大长度 netty 将会做一些特殊处理
* @param lengthFieldOffset:长度字段的偏移量
* @param lengthFieldLength:长度字段的长度
* @param lengthAdjustment:要添加到长度字段值的补偿值,如果是负数,表示启始位置往前挪几字节。如果是正数,就往后挪。
* @param initialBytesToStrip:表示获取完一个完整的数据包之后,忽略对应的 initialBytesToStrip 字节的数据
*
*/
public LengthFieldBasedFrameDecoder(
int maxFrameLength,
int lengthFieldOffset, int lengthFieldLength,
int lengthAdjustment, int initialBytesToStrip)
具体实现
new LengthFieldBasedFrameDecoder(Integer.MAX, 4, 2, -6, 6);
这边除了长度域的情况和上一种情况不一样之外,其他的都是相同的,netty 中不了解业务的具体情况,我们需要告诉它长度域后面跟多少字节就可以形成一个完整的数据包了。整体长度是 24,我们需要过滤掉表头1 和长度这两个数据长度,也是是将 6 减去,所以我们给 lengthAdjustment 赋值 -6。
LengthFieldBasedFrameDecoder总结
以上讲解的六种情况,已经可以包含市场上 90% 的应用场景了。通过参数的不同组合,可以达到不同的解码效果。用户在使用的过程中可以根据业务的实际情况进行灵活的调整。





