MongoDB mapreduce
MongoDB mapreduce
在 MongoDB 中,还提供了 map-reduce 方法来执行聚合。通常 map-reduce 方法有两个阶段:首先 map 阶段将大批量的工作数据分解执行,然后 reduce 阶段再将结果合并成最终结果。
与其他聚合操作相同,map-reduce 可以指定查询条件以选择输入文档以及排序和限制结果。
map-reduce 使用自定义 JavaScript 函数来执行映射和减少操作,虽然自定义 JavaScript 与聚合管道相比提供了更大的灵活性,但通常 map-reduce 比聚合管道效率更低、更复杂。
MongoDB mapreduce使用场景
在用 MongoDB 查询返回的数据量很大的情况下,做一些比较复杂的统计和聚合操作做花费的时间很长的时候,可以用 MongoDB 中的 MapReduce 进行实现
MapReduce 是个非常灵活和强大的数据聚合工具。它的好处是可以把一个聚合任务分解为多个小的任务,分配到多服务器上并行处理。MongoDB 也提供了 MapReduce,当然查询语肯定是 JavaScript。
MongoDB mapreduce原理
原理
MongoDB 中的 MapReduce 主要有以下几阶段:
- Map:把一个操作 Map 到集合中的每一个文档。
- Shuffle: 根据 Key 分组对文档,并且为每个不同的 Key 生成一系列(>= 1个)的值表(List of values)。
- Reduce: 处理值表中的元素,直到值表中只有一个元素。然后将值表返回到 Shuffle 过程,循环处理,直到每个 Key 只对应一个值表,并且此值表中只有一个元素,这就是 MR 的结果。
- Finalize:此步骤不是必须的。在得到 MR 最终结果后,再进行一些数据 “修剪” 性质的处理。
说明
- MongoDB 中使用 emit 函数向 MapReduce 提供 Key/Value 对。
- Reduce 函数接受两个参数:Key,emits. Key 即为 emit 函数中的 Key。 emits 是一个数组,它的元素就是 emit 函数提供的 Value。
- Reduce 函数的返回结果必须要能被 Map 或者 Reduce 重复使用,所以返回结果必须与 emits 中元素结构一致。
- Map 或者 Reduce 函数中的 this 关键字,代表当前被 Mapping 文档。
MongoDB mapreduce详解
语法
db.collection.mapReduce( function() { emit(key,value); }, function(key, values) { return reduceFunction } { query: document, out: collection } )
参数
| 名称 | 描述 |
|---|---|
| db | 数据库名。 |
| collection | 集合名。 |
| function() { emit(key,value); } | map 映射函数,负责生成键值对序列,并作为 reduce 函数输入参数。 |
| function(key, values) { return reduceFunction } | reduce 统计函数,reduce 函数的任务就是将 key-values 变成 key-value,也就是把 values 数组转换成一个单一的值 value。 |
| query | 设置筛选条件,只有满足条件的文档才会调用 map 函数。 |
| out | 统计结果的存放集合,如果不指定则使用临时集合,但会在客户端断开后自动删除。 |
MongoDB runCommand mapreduce详解
语法
db.runCommand({ mapreduce:<collection>, map:<mapfunction>, reduce:<reducefunction>, [,query:<query filter object>] [,sort:<sorts the input objects using this key.Useful for optimization,like sorting by the emit key for fewer reduces>] [,limit:<number of objects to return from collection>] [,out:<see output options below>] [,keeptemp:<true|false>] [,finalize:<finalizefunction>] [,scope:<object where fields go into javascript global scope>] [, jsMode : boolean,default true] [,verbose:true] });
参数
| 名称 | 描述 |
|---|---|
| Mapreduce | 要操作的目标集合。 |
| Map | 映射函数(生成键值对序列,作为reduce函数参数)。 |
| Reduce | 统计函数。 |
| Query | 目标记录过滤。 |
| Sort | 目标记录排序。 |
| Limit | 限制目标记录数量。 |
| Out | 统计结果存放集合(不指定使用临时集合,在客户端断开后自动删除)。 |
| Keeptemp | 是否保留临时集合。 |
| Finalize | 最终处理函数(对reduce返回结果进行最终整理后存入结果集合)。 |
| Scope | 向 map、reduce、finalize 导入外部变量。 |
| jsMode | 为 false 时 BSON–>JS–>map–>BSON–>JS–>reduce–>BSON,可处理非常大的mapreduce,为true时 BSON–>js–>map–>reduce–>BSON。 |
| Verbose | 显示详细的时间统计信息。 |
行查询的步骤
- MapReduce 对指定的集合 Collection 进行查询
- 对 A 的结果集进行 mapper 方法采集
- 对 B 的结果执行 finalize 方法处理
- 最终结果集输出到临时 Collection 中
- 断开连接,临时 Collection 删除或保留
图解
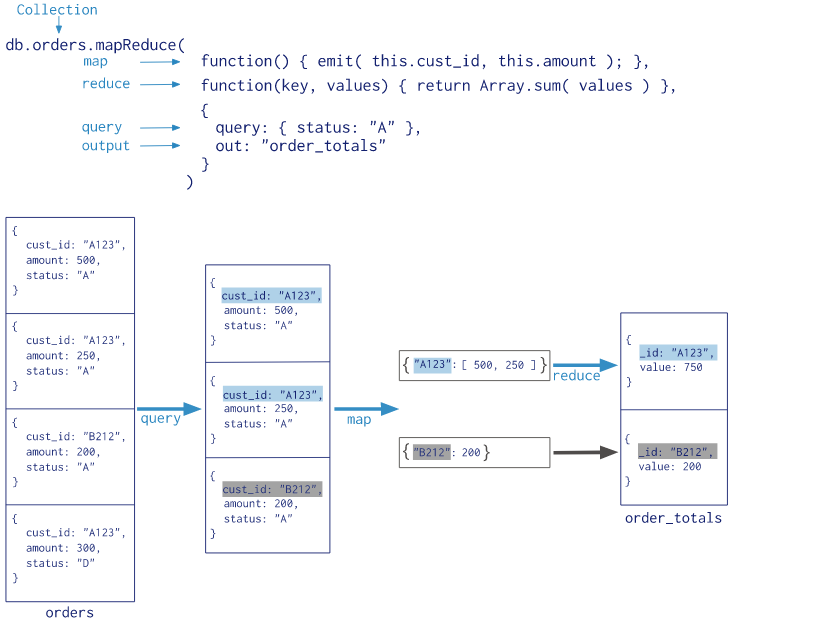
说明
Map-Reduce 的执行过程是先 map 然后 reduce 么?仔细再看一遍上文的图,不是每次 map 都有 reduce 的!如果 map 的结果不是数组,mongodb 就不会执行 reduce。很合理的处理逻辑。
对于 map 到的数据,如果在 reduce 时希望做统一的处理,一定会发现数据结果是不完整的。
案例
大于查询
我们首先,使用 mongo 命令,连接上数据库,具体命令如下:
mongo
如下图所示:

现在,我们使用 use 命令,切换到 haicoder 数据库,具体命令如下:
use haicoder
现在,我们使用 insert 插入记录,具体命令如下:
db.haicoder.insert([ {"url" : "haicoder.net", "weight" : 22}, {"url" : "m.haicoder.net", "weight" : 23}, {"url" : "www.haicoder.net", "weight" : 24}, {"url" : "http://www.haicoder.net", "weight" : 25}, {"url" : "https://www.m.haicoder.net", "weight" : 26}, {"url" : "http://m.haicoder.net", "weight" : 25}, ]);
执行完毕后,此时,如下图所示:
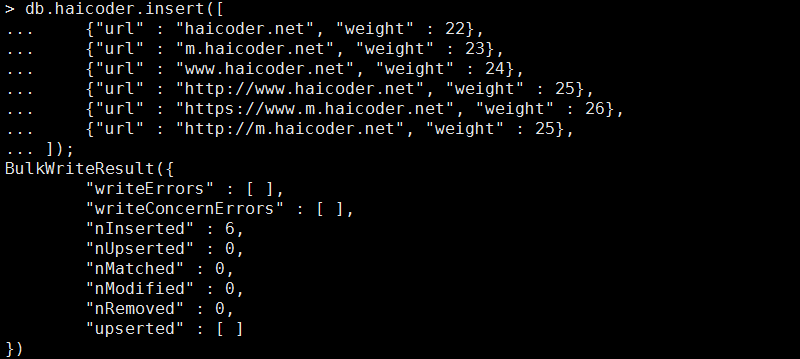
我们看到,此时提示我们成功插入了多条记录,现在,我们使用 mapreduce,查询 weight 大于 23 的记录,首先,map 的具体命令如下:
var m = function(){if(this.weight > 23) emit(this.weight,{url:this.url})};
接着,我们写 reduce 的命令如下:
var r = function(key,values){return JSON.stringify(values);}
当然,reduce 的命令也可以如下:
var r = function(key,values){ var ret={urls:values};return ret;}
生成结果集:
var res = db.runCommand({mapreduce:"haicoder", map:m, reduce:r, out:"emp_res"})
此时,全部执行完毕,如下图所示:

最终查询结果:
db.emp_res.find()
执行完毕后,最终查询结果,如下图所示:

我们看到,此时,返回了结果。
等于查询
我们查询出 weight 等于 25 的,如下:
var m = function(){ emit(this.weight,{url:this.url})}; var r = function(key,values){ var ret={urls:values};return ret;} var f=function(key,rval){ if(key==25){ rval.msg="HaiCoder";} return rval } var res = db.runCommand({mapreduce:"test",map:m,reduce:r,finalize:f,query:{weight:"25"},out:"emp_res"})
此时,全部执行完毕,如下图所示:

最终查询结果:
db.emp_res.find()
执行完毕后,最终查询结果,如下图所示:

我们看到,此时,返回了结果。
MongoDB mapreduce总结
在 MongoDB 中,还提供了 map-reduce 方法来执行聚合。通常 map-reduce 方法有两个阶段:首先 map 阶段将大批量的工作数据分解执行,然后 reduce 阶段再将结果合并成最终结果。





