MongoDB group
MongoDB group
在 MongoDB 中,aggregate 的 group 用于按指定的表达式对文档进行分组,并将每个不同分组的文档输出到下一个阶段。输出文档包含一个 _id 字段,该字段按键包含不同的组。
输出文档还可以包含计算字段,该字段保存由 $group 的 _id 字段分组的一些 accumulator 表达式的值。 $group 不会输出具体的文档而只是统计信息。
MongoDB group详解
语法
{ $group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ... } }
说明
_id 字段是必填的,但是,可以指定 _id 值为 null 来为整个输入文档计算累计值。剩余的计算字段是可选的,并使用 <accumulator> 运算符进行计算。
_id 和 <accumulator> 表达式可以接受任何有效的表达式。
MongoDB group操作符详解
操作符
| 名称 | 描述 | 类比sql |
|---|---|---|
| $avg | 计算均值 | avg |
| $first | 返回每组第一个文档,如果有排序,按照排序,如果没有按照默认的存储的顺序的第一个文档。 | limit 0,1 |
| $last | 返回每组最后一个文档,如果有排序,按照排序,如果没有按照默认的存储的顺序的最后个文档。 | - |
| $max | 根据分组,获取集合中所有文档对应值得最大值。 | max |
| $min | 根据分组,获取集合中所有文档对应值得最小值。 | min |
| $push | 将指定的表达式的值添加到一个数组中。 | - |
| $addToSet | 将表达式的值添加到一个集合中(无重复值,无序)。 | - |
| $sum | 计算总和 | sum |
| $stdDevPop | 返回输入值的总体标准偏差(population standard deviation) | - |
| $stdDevSamp | 返回输入值的样本标准偏差(the sample standard deviation) | - |
说明
group 阶段的内存限制为 100M。默认情况下,如果 stage 超过此限制,group 将产生错误。但是,要允许处理大型数据集,请将 allowDiskUse 选项设置为 true 以启用 $group 操作以写入临时文件。
技术细节
"$addToSet":expr,如果当前数组中不包含 expr,那就将它添加到数组中。"$push":expr,不管 expr 是什么值,都将它添加到数组中。返回包含所有值的数组。
案例
我们首先,使用 mongo 命令,连接上数据库,具体命令如下:
mongo
如下图所示:

现在,我们使用 use 命令,切换到 haicoder 数据库,具体命令如下:
use haicoder
现在,我们使用 insert 插入三条记录,具体命令如下:
db.articles.insert([ { "_id" : 1, "item" : "abc", "price" : 10, "quantity" : 2, "date" : ISODate("2014-03-01T08:00:00Z") }, { "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1, "date" : ISODate("2014-03-01T09:00:00Z") }, { "_id" : 3, "item" : "xyz", "price" : 5, "quantity" : 10, "date" : ISODate("2014-03-15T09:00:00Z") }, { "_id" : 4, "item" : "xyz", "price" : 5, "quantity" : 20, "date" : ISODate("2014-04-04T11:21:39.736Z") }, { "_id" : 5, "item" : "abc", "price" : 10, "quantity" : 10, "date" : ISODate("2014-04-04T21:23:13.331Z") } ]);
执行完毕后,此时,如下图所示:
我们看到,此时提示我们成功插入了多条记录,现在,我们使用 aggregate group,进行聚合查询,具体命令如下:
db.articles.aggregate([ { $group: { _id: {month: {$month:"$date"}, day: {$dayOfMonth:"$date"}, year: {$year:"$date"}}, price: {$sum: {$multiply:["$price", "$quantity"]}}, avgQua: {$avg: "$quantity"}, count: {$sum: 1} } } ]);
执行完毕后,此时,如下图所示:
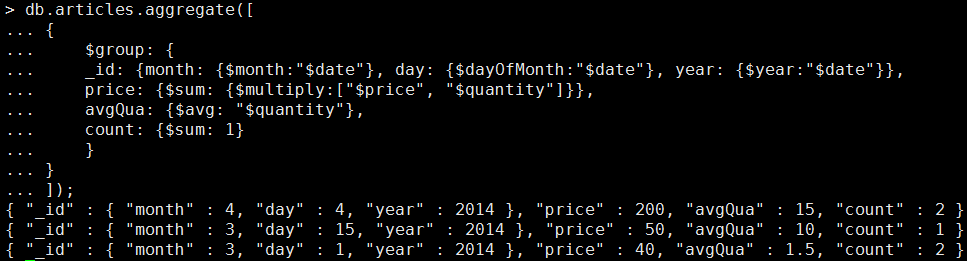
我们看到,此时返回了聚合后的结果。
MongoDB group总结
在 MongoDB 中,aggregate 的 group 用于按指定的表达式对文档进行分组,并将每个不同分组的文档输出到下一个阶段。输出文档包含一个 _id 字段,该字段按键包含不同的组。
输出文档还可以包含计算字段,该字段保存由 $group 的 _id 字段分组的一些 accumulator 表达式的值。 $group 不会输出具体的文档而只是统计信息。





