MongoDB分组第一个文档first
MongoDB分组第一个文档first
在 MongoDB 中,aggregate 的 group 用于按指定的表达式对文档进行分组,如果我们要获取每个分组后的的第一个文档,我们可以使用 first 关键字。
MongoDB first详解
语法
db_name.collection_name.aggregate([ { '$group': {'_id': '$name', 'firstField': {'$first': '$field'}} } ])
参数
| 名称 | 描述 |
|---|---|
| db_name | 数据库名 |
| collection_name | 表名 |
| _id | 分组的标志,这里将 name 相同的分为一组 |
| firstField | 自定义字段 |
| field | 分组数据的第一个 field |
说明
这里将 name 相同的数据分为一组,并返回每个分组的第一个 field。
案例
我们首先,使用 mongo 命令,连接上数据库,具体命令如下:
mongo
如下图所示:

现在,我们使用 use 命令,切换到 haicoder 数据库,具体命令如下:
use haicoder
现在,我们使用 insert 插入四条记录,具体命令如下:
db.haicoder.insert([ {id:1, "url" : "haicoder.net/c", "score" : 100 }, {id:1, "url" : "haicoder.net/cpp", "score" : 90 }, {id:2, "url" : "haicoder.net/golang", "score" : 80 }, {id:2, "url" : "haicoder.net/java", "score" : 60 } ]);
执行完毕后,此时,如下图所示:
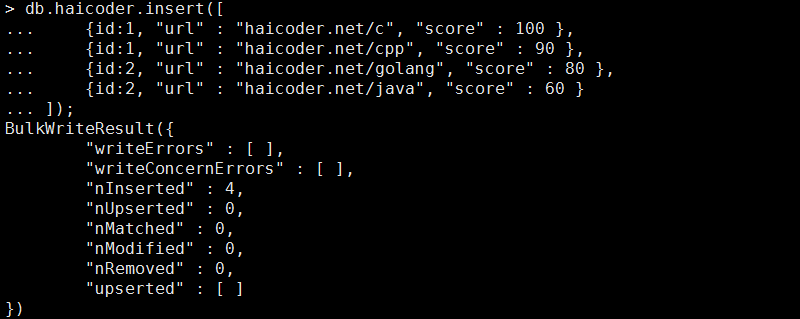
我们看到,此时提示我们成功插入了多条记录,现在,我们使用 aggregate group,进行聚合查询求分组的第一个记录的字段,具体命令如下:
db.haicoder.aggregate([ { '$group': {'_id': '$id', 'score': {'$first': '$score'}} } ]);
执行完毕后,此时,如下图所示:

我们看到,此时返回了相同的 id 的记录的第一个 score 字段,现在,我们再次查询,具体命令如下:
db.haicoder.aggregate([ { '$match': {'id': {$gt:1}} }, { '$group': {'_id': '$id', 'first_score': {'$first': '$score'}} } ]);
执行完毕后,此时,如下图所示:
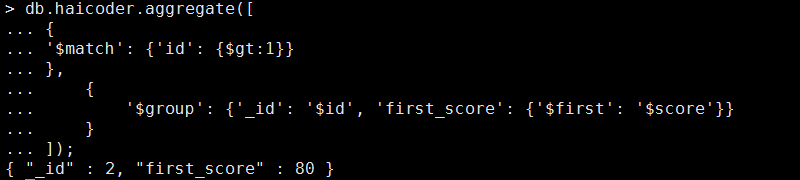
我们看到,此时我们求出了 id 大于 1 的记录的分组后的第一条记录的 score 字段。
MongoDB分组第一个文档first
在 MongoDB 中,aggregate 的 group 用于按指定的表达式对文档进行分组,如果我们要获取每个分组后的的第一个文档,我们可以使用 first 关键字。





