Elasticsearch分词器
Elasticsearch分词器教程
Elasticsearch 中默认的分词器主要有 standard tokenizer、standard token filter、lowercase token filter 和 stop token filer。
Elasticsearch分词器详解
| 分词器 | 描述 |
|---|---|
| standard tokenizer | 以单词边界进行切分 |
| standard token filter | 什么都不做 |
| lowercase token filter | 将所有字母转换为小写 |
| stop token filer | 移除停用词,比如 a the it 等等 |
案例
使用分词器
我们在 Kibana 的控制台上,输入以下代码,启用 english 停用词 token filter:
PUT /haicodernet { "settings": { "analysis": { "analyzer": { "es_std": { "type": "standard", "stopwords": "_english_" } } } } }
输入完成后,我们点击运行按钮,输出了最终的运行结果,如下图所示:

我们看到,此时我们启用停词器成功了。
停词器使用
我们在 Kibana 的控制台上,输入以下代码,测试停词器:
GET /haicodernet/_analyze { "analyzer": "standard", "text": "a dog is in the house" }
输入完成后,我们点击运行按钮,输出了最终的运行结果,如下图所示:
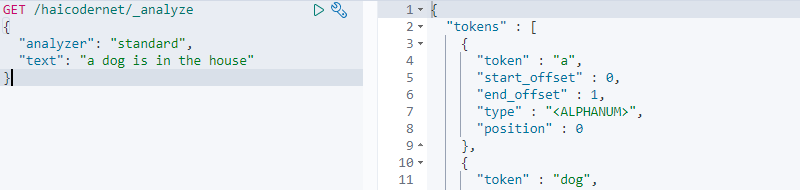
我们看到,输出了分词之后的每个词语,我们再次输入以下代码,测试停词器:
GET /haicodernet/_analyze { "analyzer": "es_std", "text":"a dog is in the house" }
输入完成后,我们点击运行按钮,输出了最终的运行结果,如下图所示:
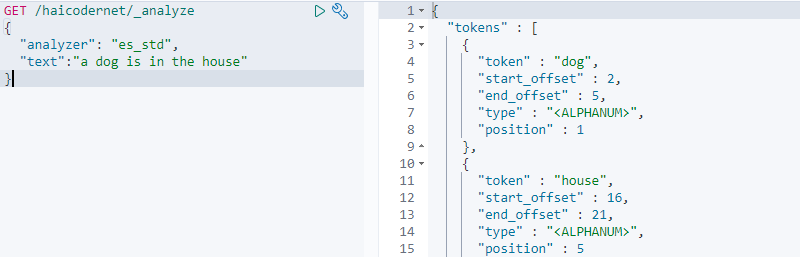
我们分析了 es_std 停词器。
Elasticsearch分词器总结
Elasticsearch 中默认的分词器主要有 standard tokenizer、standard token filter、lowercase token filter 和 stop token filer。





