Elasticsearch分组搜索
Elasticsearch分组搜索教程
我们在使用 Elasticsearch 的 DSL 进行搜索时,我们可以使用 aggs 来实现类似 sql 的 group 聚合搜索。
注意:在 Elasticsearch 5.x 之后对排序,聚合这些操作用单独的数据结构(fielddata)缓存到内存里了,需要单独开启。
Elasticsearch开启分组搜索详解
开启配置语法
PUT indexname/_mapping { "properties": { "field": { "type": "text", "fielddata": true } } }
参数
| 参数 | 描述 |
|---|---|
| indexname | 需要开启的索引名 |
| field | 需要聚合的字段 |
Elasticsearch分组搜索详解
语法
GET /indexname/_search { "aggs": { "retrurnName": { "terms": { "field": "fieldname" } } } }
参数
| 参数 | 描述 |
|---|---|
| indexname | 需要搜索的索引名 |
| retrurnName | 聚合结果返回的字段名 |
| fieldname | 需要聚合的字段 |
说明
在使用聚合操作之前,一定要对该字段开启聚合。
案例
聚合搜索
我们在 Kibana 的控制台上,输入以下代码,新建一个文档:
PUT /haicodernet/_doc/1 { "index":"www.haicoder.net", "name" : "javascript", "desc" : "javascript module", "categorys" : 5, "author" : "jobs steven", "tags": [ "javascript", "vue" ] }
输入完成后,我们点击运行按钮,输出了最终的运行结果,如下图所示:
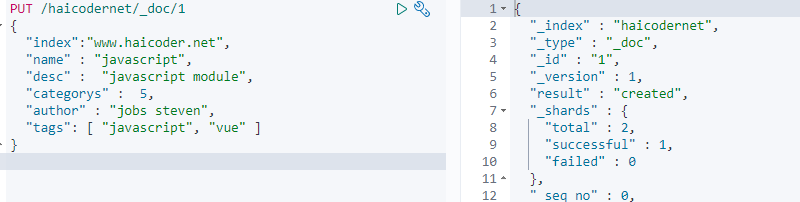
我们看到,此时我们创建文档成功了,现在,我们再次输入以下代码,再次创建一条文档:
PUT /haicodernet/_doc/2 { "index":"www.haicoder.net", "name" : "javascript", "desc" : "javascript module", "categorys" : 10, "author" : "william", "tags": [ "javascript", "dom" ] }
输入完成后,我们点击运行按钮,输出了最终的运行结果,如下图所示:
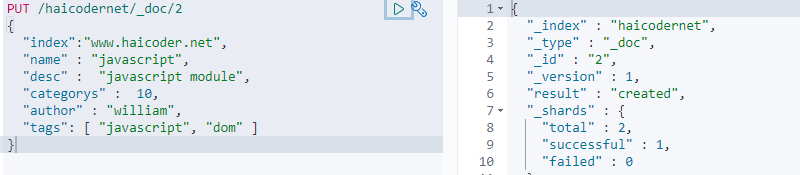
同样,我们再次创建一条记录,使用如下命令:
PUT /haicodernet/_doc/3 { "index":"www.haicoder.net", "name" : "server", "desc" : "server module", "categorys" : 14, "author" : "jobs steven", "tags": [ "server", "linux" ] }
输入完成后,我们点击运行按钮,输出了最终的运行结果,如下图所示:
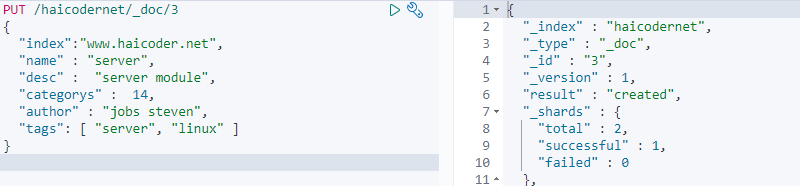
现在,我们首先对 name 字段开启聚合操作,具体命令如下:
PUT haicodernet/_mapping { "properties": { "name": { "type": "text", "fielddata": true } } }
输入完成后,我们点击运行按钮,输出了最终的运行结果,如下图所示:

现在,我们使用 DSL 进行分组搜索,具体命令如下:
GET /haicodernet/_search { "aggs": { "group_ret": { "terms": { "field": "name" } } } }
输入完成后,我们点击运行按钮,输出了最终的运行结果,如下图所示:
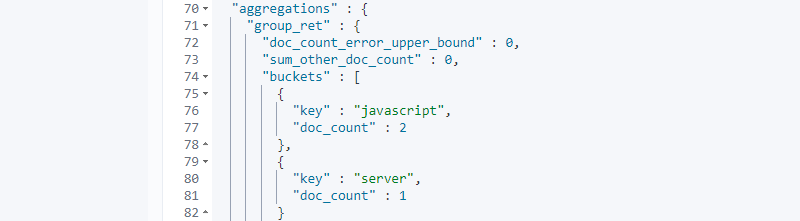
我们看到,我们最终以 group_ret 为键,返回了聚合的结果。
Elasticsearch分组搜索总结
我们可以使用 aggs 来实现类似 sql 的 group 聚合搜索。在 Elasticsearch 5.x 之后对排序,聚合这些操作用单独的数据结构(fielddata)缓存到内存里了,需要单独开启。





